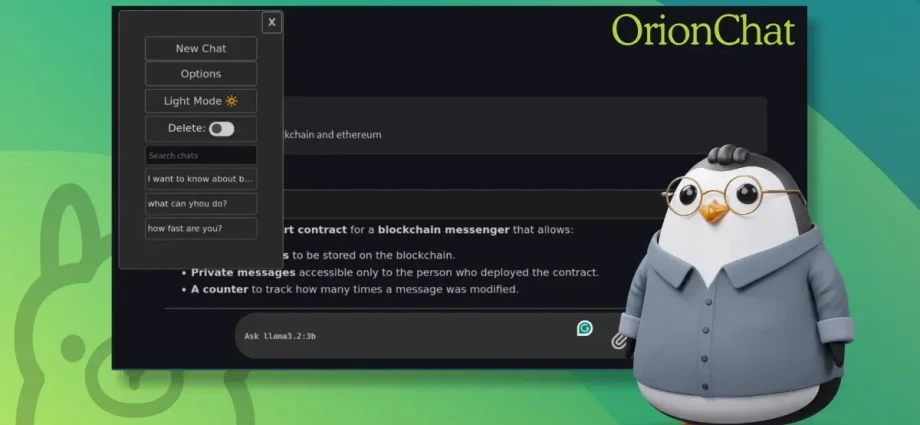
I Found a Simple Open WebUI Alternative for Running Ollama Models in a Web Browser
2026-07-31
Running local AI models has become surprisingly accessible. Install Ollama, pull a model, and you can start chatting with it in minutes. That’s exactly how I began my journey with local AI. Using an LLM directly in terminal is okayish but it limits your ability. That’s why there are soContinue Reading











